Why Developers Should Not Manage Their Own Deployments (And When to Hire DevOps Help)
Quick Answer
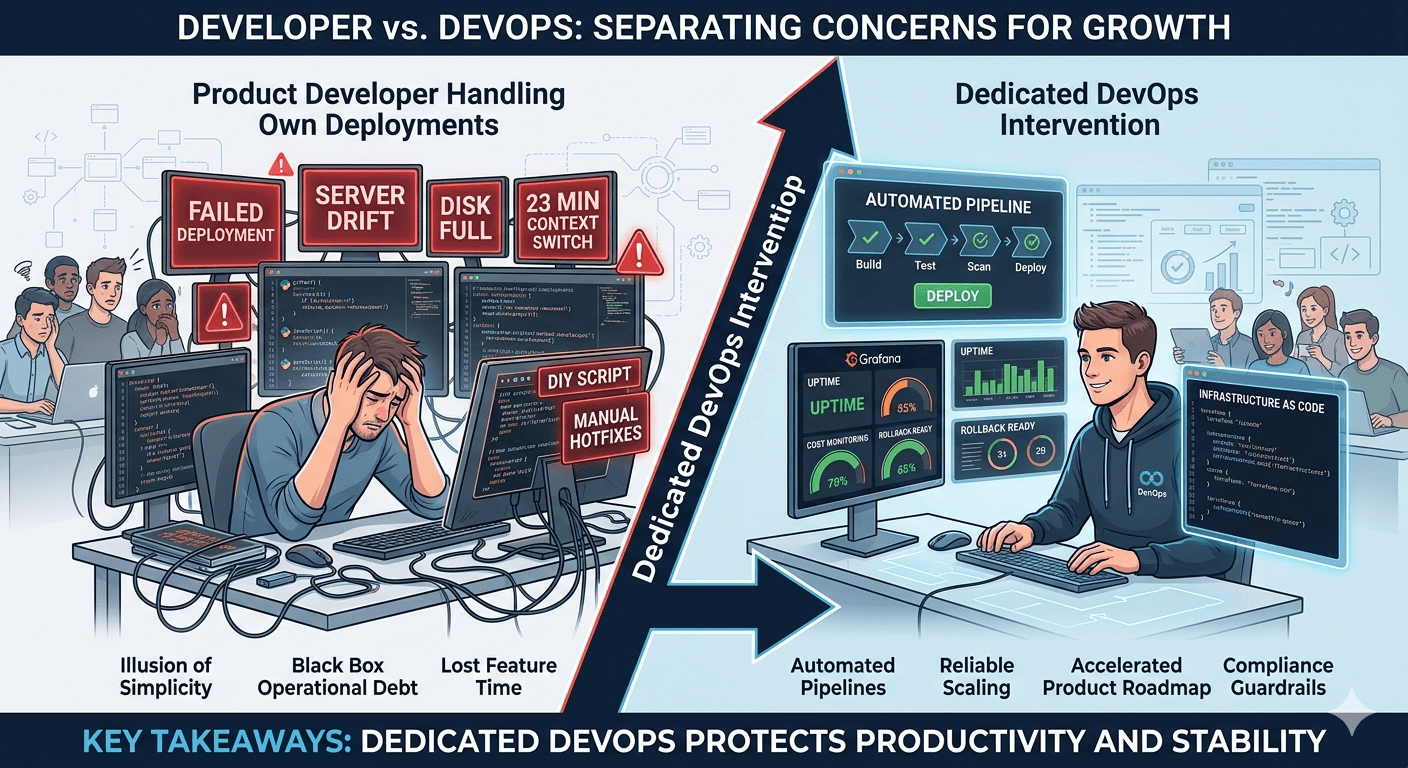
Letting developers manage servers and deployment pipelines looks like a cost saving. It is not. Senior developers lose hours to context switching, teams face unpredictable downtime, and hidden maintenance costs grow silently until they become impossible to ignore. You should hire dedicated DevOps help when your team passes five engineers, when you deploy more than ten times a week, or when security and compliance become mandatory.
In 2008, Etsy's engineering team spent weeks preparing for each deployment. Releases regularly broke the site. The team was talented. The code was solid. But the process was broken.
By 2015, Etsy deployed code more than 50 times per day. A single engineer could push updates in under two minutes. What changed? They stopped asking product developers to manage infrastructure. They built a dedicated platform team focused on automation, reliability, and developer experience.
This pattern repeats across every high-performing tech team. The real question is not whether developers can run deployments — most senior engineers can. The real question is whether they should.
When you map out DevOps versus developer responsibilities, the overlap creates friction instead of speed. Here is exactly why high-performing teams stop asking product developers to handle infrastructure, and when hiring DevOps help becomes one of the smartest growth decisions you can make.
The Core Problem: Two Jobs That Require Different Minds
DevOps and product development are not the same discipline — and treating them as one is the root cause of most startup infrastructure problems.
Product developers think in features, user flows, and state management. They need long, uninterrupted stretches of time to design systems, write logic, and test edge cases.
DevOps engineers think in failure modes, automation, and system resilience. They monitor resource utilization, design retry patterns, automate security scanning, and build rollback triggers before code ever reaches production.
The mental context switch between these two modes is expensive. Research shows developers need an average of 23 minutes to regain deep focus after an interruption. When that interruption is a failed pipeline or a misconfigured load balancer, you lose more than time — you lose engineering momentum.
Netflix understood this distinction early. They adopted an "operate what you build" culture, but with a critical difference: they provided centralized tooling so developers could own their services without becoming infrastructure experts. Developers used self-service tools like Spinnaker for deployments, while platform engineers maintained the underlying systems. This separation of concerns let product teams move fast without sacrificing reliability.
The Three Phases Where DIY Infrastructure Fails
Most teams do not fail at infrastructure overnight. They move through three predictable phases before the cost becomes undeniable.
Phase 1: The Illusion of Simplicity
In the beginning, everything runs on a single cloud instance. A developer writes a basic bash script or a simple GitHub Actions workflow. The code pushes, the server restarts, the app loads. Adding a full-time infrastructure role feels like overkill.
At this stage, the system is genuinely simple — one environment, one deployment target, full control over every dependency. The script works because the system state matches the local machine exactly. The assumption is that this will scale.
It will not.
Phase 2: The Drift and Context Switching Trap
Growth changes everything. You add a staging environment, a background worker, a managed database. Suddenly your deployment script needs to handle environment variables, database migrations, and health checks.
The hidden maintenance tax begins here. The script breaks when a dependency updates. A disk fills during a traffic spike. Someone has to wake up and rotate logs, clear space, or patch a security vulnerability. The developer who wrote the script is now the only person who understands it.
Every hour spent debugging ingress routes or fixing pipeline timeouts is an hour stolen from product work. When that interruption requires a 23-minute recovery to regain focus, even a brief infrastructure incident costs half a morning.
Phase 3: The Black Box and Operational Debt
When disorganized infrastructure meets a growing team, tribal knowledge replaces documentation. Only one person knows how to roll back a failed release. New hires take weeks to understand the deployment process. The environment behaves differently in production than it does locally.
The system becomes an expensive black box:
Outdated libraries stay outdated because upgrading might break the pipeline
No rollback strategy means bad releases require manual intervention and user downtime
Security patches are applied reactively, not automatically
Compliance audits fail because access controls were never standardized
At this point, you are not saving money by avoiding DevOps help. You are paying for it in delayed features, unstable releases, and frustrated engineers.
The Real Hidden Costs of DIY Deployment
Founders often treat DevOps as an added expense. In reality, avoiding it creates four categories of hidden cost that grow silently until they explode.
| Hidden Cost | What It Actually Means |
|---|---|
| Lost feature time | A senior engineer spending 20% of their week on pipelines and logs is thousands of dollars diverted from product development — every single week |
| Downtime expenses | Unoptimized infrastructure means longer incident response. Revenue loss during outages is obvious. The indirect loss from user trust damage and support spikes is worse |
| Deployment technical debt | Ad hoc scripts without rollback strategies create hidden traps — they work until they do not, and they break during the busiest day of the quarter |
| Onboarding friction | New engineers should spend their first week learning your product, not untangling server configurations from two years ago |
Etsy's transformation makes the upside concrete. Before their DevOps investment, a single deployment required three developers, one operations engineer, and a production engineer on standby. After automating their pipeline with Deployinator, one person could push in under two minutes. That is not just a time saving — it is a fundamental shift in how the team spends its energy.
Exactly When to Hire DevOps Help
Most startups do not need a full-time DevOps engineer on day one. But waiting until production crashes is a costly mistake.
The right time to hire DevOps help is not a specific headcount. It is when infrastructure friction actively blocks your product roadmap.
Here are the four concrete signals:
Signal 1: Team Size and Release Frequency
If you have more than five engineers sharing a single codebase, manual deployments will cause conflicts. Developers will overwrite each other, environment variables will drift, and merge conflicts will block releases. If you deploy more than ten times a week but your CI pipeline takes over fifteen minutes or fails regularly, you need dedicated automation ownership.
Signal 2: Architecture Complexity
When you move from a single server to multiple services, regions, or databases, simple scripts fall apart. Microservices require health checks, retry logic, and distributed tracing. Multi-region setups need load balancing and data synchronization. This requires deliberate infrastructure design — not patchwork fixes written by whoever touched the code last.
Signal 3: Security and Compliance Requirements
If customers are asking about SOC 2, HIPAA, or ISO 27001 compliance, auditors will not accept "we will fix it later." Compliance requires strict access controls, audit logging, encrypted data flows, and documented change management. A dedicated DevOps professional builds these guardrails without blocking developer workflow — and automates policy checks so developers stay compliant without changing their daily process.
Signal 4: Alert Fatigue
If your engineering team spends more than 15 to 20 percent of their week answering alerts, fixing servers, or managing deployments, you have already passed the tipping point. When developers treat infrastructure warnings as background noise instead of actionable signals, small issues become major outages.
What Dedicated DevOps Actually Fixes
Dedicated DevOps ownership removes operational friction, accelerates feature shipping, and stops developer burnout before it starts.
The shift is concrete, not theoretical:
Deployment time goes from hours to minutes with automated pipelines
Security checks run automatically before code reaches production, not after
Cost monitoring catches oversized servers before they drain the budget
Rollback strategies exist before bad releases happen, not during them
Onboarding time drops because infrastructure is documented and reproducible
Developer focus returns to building the product that generates revenue
Netflix's 2008 database corruption took down service for three days. Instead of patching the problem, they rebuilt their entire platform on AWS with microservices, automated testing, and chaos engineering tools. This upfront investment in dedicated platform engineering allowed them to scale to 214 million subscribers with minimal operational overhead. The investment in infrastructure ownership paid back in reliability that a developer managing deployments as a side project could never provide.
DevOps vs Developer: Core Responsibility Comparison
| Dimension | Product Developer | DevOps Engineer |
|---|---|---|
| Primary focus | Features, user flows, business logic | Reliability, automation, failure prevention |
| Thinks about | What the app does | How the app keeps running |
| Works in | Long uninterrupted focus blocks | Reactive and proactive system monitoring |
| Success metric | Features shipped, bugs fixed | Uptime, deployment frequency, recovery time |
| Infrastructure role | Consumer of infrastructure | Owner of infrastructure |
| When interrupted | Loses 23 minutes of deep focus | Interruption is the job |
Mixing these responsibilities does not make your product developer stronger. It makes both jobs worse.
Key Takeaways
Developers can handle deployments — but should not. Mixing product development with infrastructure management creates context switching that costs 23 minutes of focus per interruption
DIY deployment has four hidden costs: lost feature time, downtime expenses, deployment technical debt, and slow onboarding — all of which grow silently
Three phases of DIY failure: the illusion of simplicity, the drift and context switching trap, and the black box of operational debt
Four signals it is time to hire DevOps help: team over five engineers, more than ten deploys per week, architecture complexity, or security and compliance requirements
Dedicated DevOps is not an expense — it is protection for your developer productivity, your release stability, and your product roadmap
The Etsy example: before dedicated DevOps, one deployment needed five people and weeks of preparation; after, one person pushed in under two minutes
Frequently Asked Questions
What is the difference between a developer and a DevOps engineer? A developer builds the application — features, APIs, and business logic. A DevOps engineer owns the system that delivers and runs that application — pipelines, infrastructure, monitoring, and reliability. The skills overlap but the focus does not.
When should a startup hire a DevOps engineer? When infrastructure friction starts blocking the product roadmap. Concrete signals include a team of more than five engineers, more than ten weekly deployments, architecture with multiple services or regions, or compliance requirements from enterprise customers.
Is it cheaper to let developers handle DevOps? Not in practice. The hidden costs — lost feature time, unplanned downtime, slow onboarding, and mounting technical debt — consistently outweigh the salary savings of not hiring dedicated DevOps help.
What does a DevOps engineer actually do day to day? They design and maintain CI/CD pipelines, manage cloud infrastructure, automate security scanning, build monitoring and alerting systems, write infrastructure as code, manage secrets and access controls, and respond to production incidents.
Can a small startup afford DevOps help? Yes — dedicated DevOps help does not always mean a full-time hire. Fractional DevOps engineers, platform consulting, and managed infrastructure services are common options for early-stage teams that need infrastructure ownership without the cost of a full-time senior hire.
If your team is spending more time fixing pipelines than shipping features, the infrastructure is no longer serving the product — it is blocking it.
That is the exact moment to change the model.